

Introduction
Hoping you were able to get your ollama up and running. Before i get into how to build a local Chatbot I want to explore a key component which is Vector databases. I will be honest, I thought i knew everything that i needed to know regarding databases as a technical PM. But this somehow fell through the cracks! Are you with me? lets rollup and dig-in!
Problem with Keyword Search
Before we understand the needs, I would like to explore how vector databases work. You must be wondering, are you a real PM? hold it and hear me out.
The idea behind the operation of vector databases is that while a conventional database is optimised for storing and querying tabular data consisting of strings, numbers and other scalar data, vector databases are optimised for operating on vector-type data. Therefore, query execution on a vector database differs from query execution on a conventional database. Instead of searching for exact matches between identical vectors, a vector database uses similarity search to locate vectors that reside in the vicinity of the given query vector within the multidimensional space.
In a traditional database, How do you execute a query that returns your exact match and all the products that reside in the vicinity? Yes you did read it right, in the vicinity of your data. It might sound like an alien concept and not make any sense. Lets figure it out. For that, we need to go to the use case.
Imagine you have an ecommerce site. Think of a use case where when a user searches for a couch, you also want to list all the related products in the category such as sofa, futon etc… in a traditional rdbms you could maintain an intersection table of sorts or a mapping table to manage these relationships. As and when you add a new product, you also need update entires for these mappings, so you are current. Now think of all the combinations across product categories, this could get really messy real quick. Is vector database making sense now?
Enter Vector Databases
Instead of storing data as text or numbers, vector databases store data as vectors. A vector is essentially a list of numbers that represents the meaning of the data. Think of it like this:
Text: The phrase "Happy Birthday" might be represented as a vector that captures its emotional sentiment.
Images: A picture of a cat would be represented as a vector that captures its visual features (shape, color, texture).
Audio: A recording of a specific song might have a vector that represents its melody and rhythm.
These vectors are created using sophisticated machine learning models. When you search in a vector database, you're not searching for matching words; you're searching for vectors that are similar to your search query's vector.

Here is an example how product information is stored in a relational database versus a document store versus a vector database collection
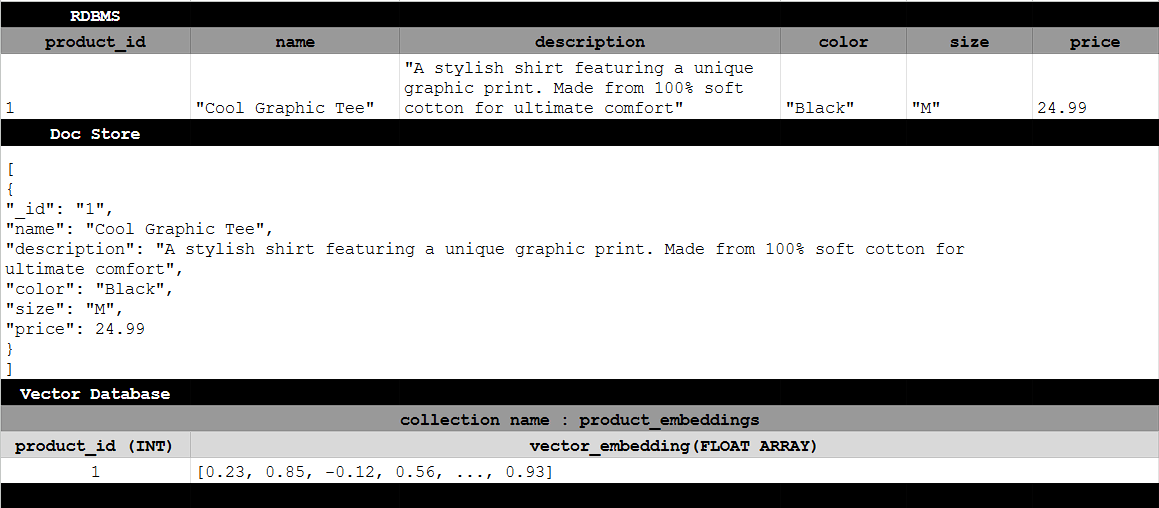
if you want to dig further and understand how these texts and images are converted to vectors embeddings, many NLP algorithms do that for you, you can read about them here
Why This Matters for Product Managers
So why should product managers care about vector databases? Here's how they unlock new possibilities:
Improving Search in your Product - Go beyond elastic. Imagine a search bar that truly understands what the user means, even if they're not using the exact keywords.
Recommendation systems - Provide users with hyper-relevant products, content, or information based on their specific interests and behavior.
Semantic Search - Enable users to explore your data with a deeper understanding of meaning and context.
More Powerful AI Applications - The core technology to build more intelligent applications, including chatbots, image recognition, and more.
Competitive Advantage - Companies that leverage vector databases gain an edge by delivering superior user experiences and more meaningful interactions.
Key Concepts (Simplified):
Embeddings: The process of converting data into numerical vectors.
Similarity Search: Finding vectors that are closest to the query vector.
Distance Metrics: Algorithms to measure the similarity between vectors (e.g., cosine similarity).
Examples in Action:
E-commerce: Finding clothes that match a user's style, even if they haven't explicitly searched for certain characteristics.
Content Platforms: Recommending articles or videos that are conceptually related to what a user has already watched.
Customer Support: Finding the best solution to a customer's problem by understanding the underlying issue, not just their keywords.
Looking Ahead
Vector databases are revolutionizing how we interact with data, especially as we move towards more intelligent AI-powered applications. While the technical details can get complex, understanding the fundamentals is crucial for product managers to envision and build the next generation of user experiences.
In our next post, we'll get hands-on. We'll dive into building a local AI chatbot using Deepseek-r1, Pinecone, and Grader. You'll see exactly how these tools work together to leverage vector databases and bring intelligent conversations to life. Stay tuned!
Call to Action:
What are some use cases you can envision for vector databases in your own products? Share your thoughts in the comments below!
Appendix
A detailed explanation on Vector embeddings from a Google AI Engineer
A simple and easy to understand explanation from the CTO of Datastax
A great video by Oracle if you prefer that