
O[lla]-ma-God - How to run LLM locally

Introduction
If you've been paying any attention to tech news lately, you've likely heard about Deepseek. It's made waves, even sparking debate about its implications for major players in the AI space. Is it a legitimate challenge to the trillion-dollar tech giants in Silicon Valley, or just hype? We will certainly find out.
Before we delve deeper into Deepseek, I want to go back to the OG of open-source model: Meta's Llama. Meta's commitment to open source is something I find particularly admirable. It's a key component of their overall strategy.
So, how can one explore Llama?
Honestly, AI/ML isn't my day-to-day job. I've been putting a lot of time into learning about it, even making a plan to switch to an AI/ML-focused tech PM role. To get some real experience, I started with Llama. But, Llama just gives you an LLM that you interact with using the command line/terminal. What if you want to try other models or have a more user-friendly way to interact with the model? Where do you go then? That's where Ollama comes in.
Download and Install Ollama. Just to check, on the terminal. This should work but if it’s not ‘recognized’ check your environment variables.
C:\Users\username>ollama Usage: ollama [flags] ollama [command]
C:\Users\username>ollama listExplore the models that are available here. Lets pick the lightest to test it out -llama3.2. You could pull a model from the registry by
C:\Users\username>ollama pull llama3.2
You also have access to other models forked and fine-tuned for specific use cases. with our basic model, your average computer should be able to handle it. But if you happen to have a power PC with multiple cores and a GPU thats supported by ollama, knock yourself out. Here is a list of all the GPUs supported by ollama and if you have a recommendation for a GPU, please put that in the comment section below! Next lets make it user-friendly.
Attach a UI
Now lets figure out how we attach a UI.
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted AI platform designed to operate entirely offline. It supports various LLM runners like Ollama and OpenAI-compatible APIs, with built-in inference engine for RAG, making it a powerful AI deployment solution.
Pre-requsite: Docker Desktop. You knew this coming :) Docker just makes things a lot easier.
Download and Install Docker Desktop on your device.

Next search for open-webui and install. You are now all set. There are clear instructions on how to (if you run into trouble) here.
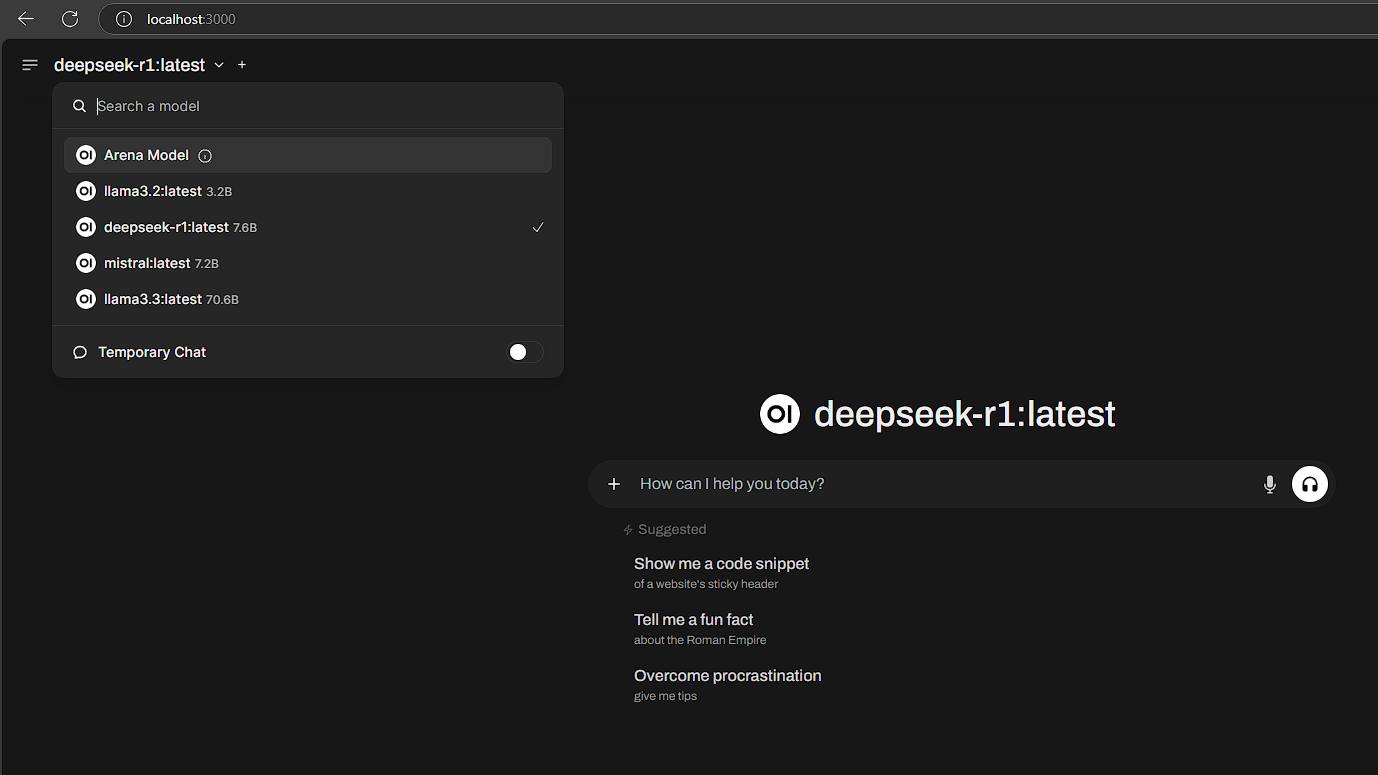
Now navigate to localhost:3000 on your browser and you got yourself an LLM running locally. Ask away!
Conclusion
If you're wondering why I'd bother with all of this when I could just use ChatGPT or Gemini, my end goal is to have an LLM that runs locally, trained on my own data, to answer questions. Wouldn't that be cool? I mean, that's what most companies are trying to do. So, it's going to be a good learning experience and you as the technical PM will be one tasked to execute on it, duh!